La idea que principal de las redes inalámbricas es pode trasmitir los datos generados o almacenados en una aplicación de un dispositivo a otro dispositivo remoto. La trasmisión de estos datos ha de ser lo más rápido posible y al ser un medio compartido que donde pueden haber interferencias, se ha de integrar algunos mecanismo que permitan recuperar los datos en caso de que parte en algún de la emisión éstos se hayas visto corrompido.
Hemos de tener en cuenta que los datos normalmente son representados por bits (unos y ceros), pero las redes inalámbricas trabaja por señales analógicas representadas por ondas. Es por eso que para poder cumplir todo lo mencionado anteriormente, se hace meter en el juego lo que se denomina modulación y codificación.
Si nos centramos en la modulación podríamos decir que consiste en representar mediante ondas cada bits de datos que se ha de propagar de un dispositivo a otro por el aire. Las cualidades que se utilizan para modificar las ondas son las siguientes:
- Amplitud: es la fuerza con la que se emite la señal en función de si la potencia sigue constante podemos decir que el valor del bit es 0 y cuando hay cambio en la amplitud quiere decir que se envía un 1. En OFDM por ejemplo se utilizan varios intervalos de amplitud para poder representar múltiples bits.
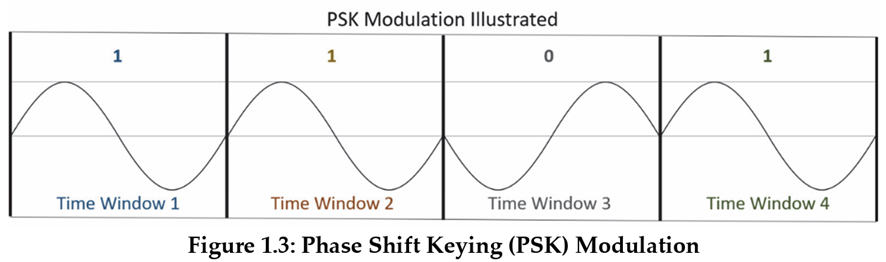
- Fase: se utiliza en comparación con otra onda. Si la fase es la misma, esta en fase y la potencia se duplica. En cambio si están desfasado 180º la señal se suprime. Si en un momento de la señalización la fase cambia, el valor cambia, en caso contrario el valor se mantiene.
Los tipos de modulación se pueden usar de forma simultánea para poder trasmitir más bits.
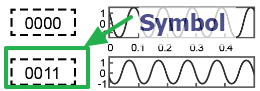
Al total de bits que se permite enviar mediante los diferentes tipos de modulación se le denomina Symbols = #waveform
Mientras mas datos que queramos enviar en un determinado espacio de tiempo, más cambios en las ondas se han de poder realizar. De manera que si por ejemplo una onda permite 4 formas distintas (ya sea en cambio de fase o de amplitud) podríamos llegar a representar 16 bits. La función para saber el numero de bit en una waveform se puede obtener mediante la operación 2x.
Ej. Si elevamos 2 a la 8 (8 formas diferentes de onda) podemos llegar a representar 256 bits.
A la cantidad de bits que se pueden representar con una waveform se le denomina "symbol"
Mientras más datos se quiere enviar más compleja debe ser la modulación y mejor la calidad de la señal. A continuación hay una captura de la constelación usada por OFDM de 64 QAM (modula modificando la fase y la amplitud simultáneamente) donde se detalla la cantidad de símbolos que se pueden combinar. Como podemos ver cada símbolo esta representado por 6 bits
A partir de este punto interviene el "Data Encoding"
Data Encoding: es el proceso que usado para convertir los datos que provienen de la aplicación en ondas de radio (waveform) para poder ser enviadas por el aire y ser descodificadas en el destino. El mecanismo que se utiliza es la modulación.
Como hemos comentado también recomendable disponer de un mecanismo para poder recuperar estos bit que se envían en caso que la señal se pueda ver afectada por alguna interferencia. Aquí entra en acción un elemento denominado Convultional Coding. Este mecanismo permite corregir errores antes de que la trama pase por el proceso de CRC y sea descartado si hay algún error. Para ello se introduce bits adicionales para poder hacer esa corrección de errores. Estos bits de añaden desde el inicio de la trasmisión y el proceso de corrección se denomina Forward Error Correction (FEC). El "coding rate" especifica del total de bits enviados representan datos útiles y el número de bits que se utilizan para recuperación de datos en caso de interferencias. En ratio se representa en forma de fracción como por ejemplo 2/3. En este ejemplo la interpretación sería que de cada 3 bits enviado sólo hay dos bits que representan datos útiles y 1 más para recuperación de datos en caso de corrupción de la señal. Mientras mas bits utilizados para la corrección de datos, menor es el data rate que se consigue.
Como hemos comentado, cuando trasmitimos mediante Wifi usamos Coding Rate para recuperar datos en caso de interferencia. Por lo que si queremos trasmitir 12000 bit el tamaño final del paquete aumenta para aplicar la codificación. En 2/3 aumentaría a 18000.
En OFDM tenemos 48 subportadoras de datos. Si modulamos en 64-QAM permitimos enviar 6 bit por símbolo. 6 bit x 48 subcarrier = 288 bit/sim .
Para poder trasmitir los 18 000 bits necesitaríamos 63 símbolos (18000/288).
En OFDM la trasmisión de un símbolo dura 3.2 µ . Una vez realizada la trasmisión el receptor ha de esperar un tiempo antes de volver a trasmitir el siguiente símbolo para permitir que la trama anterior llegue al destino y las trasmisiones no se solapen. A este intervalo de tiempo se le denomina "Guard Interval". Existen dos intervalos, el "Short Guard Interval" SGI que tiene una duración de 0.4 microsegundos o el "Long Guard Interval" LGI que tiene una duración de 0.8 microsegundos
Si usamos LGI necesitaríamos para trasmitir cada símbolo. En total para trasmitir los 18000 bits necesitaríamos 252 µs (63 símbolos * 4µs para trasmitir cada símbolo)
Los anchos de banda conseguidos en función del ratio de codificación se puede consulta en la tabla de MCS index. Ahí aparecen todos los valores en función de la tecnología PHY usada y amplitudes de canal.
Un elemento que influye a la hora de decidir que modulación utilizada es el SNR. Mientras mas bajo es el SNR menor es el coding rate y menos bits de datos útiles se envían, pero más tolerante a corrección de errores.
Visto todo lo anterior solo quedaría un punto. ¿Cómo se calcula el data rate que aparece asociado a cada modulación?
Recordemos que OFDM cuando se modula para 802.11n y 80211ac dispone de 52 subportadoras para el envío de datos. Recordemos que cada símbolo se trasmite en 3.2µs + 0.8µs de LGI. Para obtener las transmisiones que se realizan en un µs se ha de dividir las 52 subportadoras entre 4 µs, lo que nos da un total de 13 transmisiones cada µs. Si lo pasamos a segundos, 1µs = 1.0E-6 s
13 trans/1.0E-6 s= 13*10E6 = 13000000 trans/seg (13M trans/seg)
Vamos a ver como calcularíamos el data rate para 256-QAM. Esta modulación permite enviar 8 bit por símbolo. Si tomamos como referencia un coding rate de 2/3 con LGI, tendríamos que multiplicar los 13.000 retrasmisiones que se hacen por segundo por los 8 bit que se envían por trasmisión lo que nos.
13M Tras/seg * 8bit/1 Trans = 104 Mbps
Si usamos usamos un coding rate de 3/4 nos queda los siguiente:
104 Mbps * 3/4= 78 Mbps
Si usamos SGI tenemos que el numero de trasmisión por segundo es 14.4 (52/(3.2µs+04µs)
14.4M Tras/seg * 8 bit/1tra = 115 Mbps
Si usamos usamos un coding rate de 3/4 nos queda los siguiente:
115 Mbps * 3/4 = 86.2